What is Chainquery
Mark Beamer • May 24 2018
Chainquery makes LBRY blockchain data significantly more accessible and useable
By default, data from the LBRY blockchain is basically a raw dump of data in a compressed format:
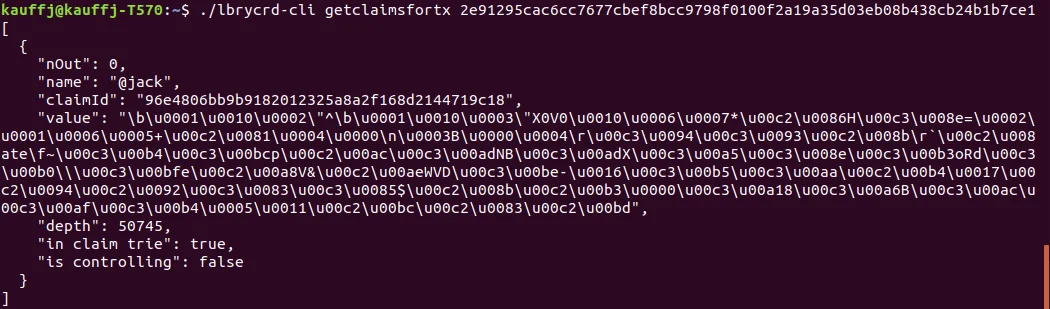 In addition to extracting this data, you'd have to run several hundred thousand commands to get the same data returned by a single command below.
In addition to extracting this data, you'd have to run several hundred thousand commands to get the same data returned by a single command below.
Since blockchain data is raw, compressed, and not accessibly structured, most blockchains have specifically designed methods to create more usable forms of the data.
In the case of LBRY, Chainquery is both the easiest and most feature-rich method of doing that to date.
What does Chainquery do?
Chainquery takes all the raw data in the blockchain, decompresses and extracts it, and stores it in a relational database, all in real-time. This allows the rich features of SQL to be applied to live blockchain data.
This is all rather abstract, so let's look at an example. Suppose we wanted to determine the 10 LBRY URLs with the largest number of staked Credits. Without Chainquery, this would require making direct calls to the LBRY blockchain API, iterating over each claim, and storing the 10 largest. In addition to being non-trivial to write, it would also be quite slow.
With Chainquery, it's about a hundred characters of performant SQL:
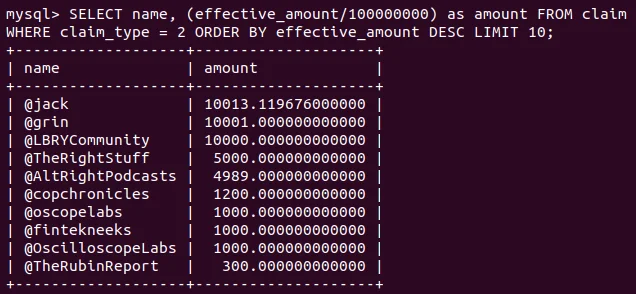
Virtually any application that is interested in displaying or operating off of data stored in the LBRY blockchain can benefit from Chainquery.
You can see the full schema for Chainquery here.
Why is Chainquery exciting?
Chainquery is exciting, anyone in the world interested in building on top of LBRY, as well as internal LBRY team members, can do so much, much more efficiently.
LBRY team members will be able to save significant time when working on any features that depend at any point on blockchain data. No longer do we have to develop complex data handling or transformations for a new feature that works around the specific formats coming out of the blockchain. We can now "Chainquery it". Indeed, Chainquery will see internal use in at least four projects: search, explorer, rewards, and spee.ch!
For our community and users, this means features will come faster and work better. We will be less encumbered by the raw and compressed format of the blockchain and not re-implement similar functionality multiple times over.
Additionally, community contributors and other technical users can use Chainquery to build something on top of LBRY. Anyone can run their own Chainquery instance and access blockchain information via SQL queries.
How do I use Chainquery?
Most LBRY users do not need to use Chainquery directly and instead will simply benefit from the increased engineering capabilities and performance it allows us internally.
However, if you're interested in using it directly or poking around with the data, all of our code is open-source and available on GitHub. Detailed setup instructions are inside of the repository.
Additionally, at least for now, we've provided a public, readonly MySQL server you can connect to. This is a generic SQL API that is accessible from an HTTP GET and returns JSON data. You can even use it in your browser!
Get the latest block information:
https://chainquery.lbry.com/api/sql?query=SELECT * FROM block ORDER BY height DESC LIMIT 1
Get all claims and their details for the name "lbry":
https://chainquery.lbry.com/api/sql?query=SELECT * FROM claim WHERE name = "lbry"

Mark Beamer is an inveterate entrepreneur. Ever since he founded his first company (Beamer Lawn Service) at 16, he's pursued new and interesting business ideas.
While running his first computer business, Mark discovered the joys of coding - especially the joys of using coding to eliminate annoying tasks with automation.
His continued passion for software led him to close the business after 4 years and pursue a BS in computational science and mathematics.
Mark has been developing software ever since. He found LBRY summer of 2017 on a leisurely weekend, saw the coding maxims and was sucked in instantly. LBRY has been his focus since.